
Mengenal Apache Spark
Apache Spark merupakan framework open-source yang didesain untuk menangani pemrosesan data dalam skala besar dengan kecepatan tinggi dan efisiensi optimal. Berbeda dari sistem tradisional seperti Hadoop MapReduce, Spark memanfaatkan pemrosesan berbasis memori (in-memory processing), sehingga data diolah langsung di RAM dan mempercepat kinerja secara signifikan.
Framework ini kompatibel dengan berbagai bahasa pemrograman seperti Python (PySpark), Scala, Java, hingga R. Spark juga menyediakan pustaka internal yang lengkap, meliputi Spark SQL, MLlib untuk pembelajaran mesin, GraphX untuk pengolahan graf, serta Structured Streaming untuk data streaming.
Pentingnya Apache Spark bagi Seorang Data Scientist
Seorang data scientist kerap dihadapkan pada tantangan mengolah data berukuran besar dengan kecepatan proses yang tinggi. Dalam konteks inilah Apache Spark menunjukkan keunggulannya:
- Performa Tinggi: Proses di memori mengurangi ketergantungan pada disk I/O.
- Fitur Lengkap: Menyediakan fungsi untuk machine learning, pemrosesan data streaming, hingga kueri SQL.
- Skalabilitas Fleksibel: Efektif untuk skala data kecil hingga puluhan terabyte.
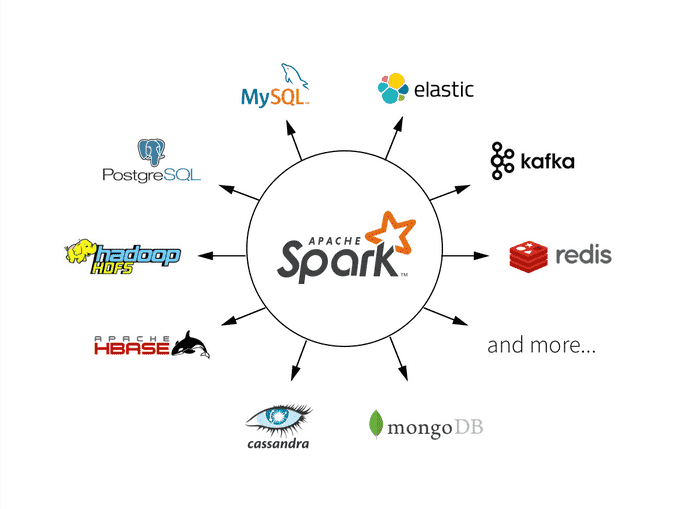
- Kemudahan Integrasi: Dapat bekerja bersama berbagai sistem penyimpanan seperti HDFS, Cassandra, Amazon S3, dan lainnya.
Siapa Saja yang Memanfaatkan Apache Spark?
Beragam sektor dan profesi menggunakan Apache Spark untuk mendukung aktivitas data-driven mereka:
- Data Scientist & Analis Data: Untuk proses eksplorasi dan analitik data yang cepat.
- Perusahaan Teknologi Besar: Misalnya Netflix, Uber, dan Facebook memanfaatkan Spark untuk analisis data pengguna secara real-time.
- Akademisi & Peneliti: Dalam eksperimen skala besar di ranah data science.
Di Mana Apache Spark Bisa Dijalankan?
Spark dapat beroperasi di berbagai platform komputasi, seperti:
- Komputer Lokal: Cocok untuk pengujian atau proses pembelajaran.
- Cluster Komputasi: Termasuk dalam ekosistem Hadoop YARN, Apache Mesos, atau Kubernetes.
- Layanan Cloud: Tersedia dalam platform seperti AWS EMR, Azure HDInsight, dan Google Cloud Dataproc.
Kapan Apache Spark Paling Efektif Digunakan?
Gunakan Spark ketika Anda:
- Menangani proyek dengan volume data besar (big data).
- Memerlukan pemrosesan data yang cepat dan efisien.
- Ingin menganalisis data real-time dari sumber seperti media sosial atau perangkat IoT.
- Mengembangkan model machine learning berskala besar.
Langkah Awal Menggunakan Apache Spark
Untuk memulai penggunaan Apache Spark, Anda bisa mengikuti langkah berikut:
- Install Spark pada komputer lokal atau dalam lingkungan cluster.
- Tentukan bahasa pemrograman yang akan digunakan (misalnya Python melalui PySpark).
- Muat data dari berbagai sumber seperti CSV, database, HDFS, atau API.
- Lakukan transformasi dan analisis data menggunakan DataFrame atau RDD.
- Simpan hasil analisis atau visualisasikan sesuai kebutuhan.
Contoh Kode PySpark Sederhana
pythonCopyEditfrom pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Contoh").getOrCreate()
data = spark.read.csv("data.csv", header=True, inferSchema=True)
data.show()
Penutup
Apache Spark merupakan salah satu alat yang paling dibutuhkan dalam dunia data science modern. Dengan kemampuan memproses data dalam jumlah besar secara cepat, fleksibel, dan terintegrasi, Spark menjadi solusi tepat bagi siapa saja yang ingin mengeksekusi proyek big data dan analitik secara efisien.
Baca Juga:Heatmap: Cara Menyulap Data Kompleks Jadi Mudah Dipahami
Leave a Reply