Mengapa Kita Perlu Memahami ETL?
Di era di mana data menjadi “minyak baru”, pertanyaannya bukan lagi apakah kita punya data—tetapi seberapa cepat dan akurat kita bisa mengolahnya. Di balik dashboard interaktif dan analisis canggih, ada satu proses penting yang sering luput dari perhatian: ETL (Extract, Transform, Load).
Extract, Transform, Load adalah fondasi di balik data analytics, business intelligence, dan machine learning. Tanpa ETL, data akan tetap tersebar, tidak konsisten, dan sulit dimanfaatkan secara strategis.
Apa Itu ETL dan Mengapa Ia Penting?
Extract, Transform, Load adalah proses inti dalam integrasi dan manajemen data. Tiga tahapannya masing-masing punya peran krusial:
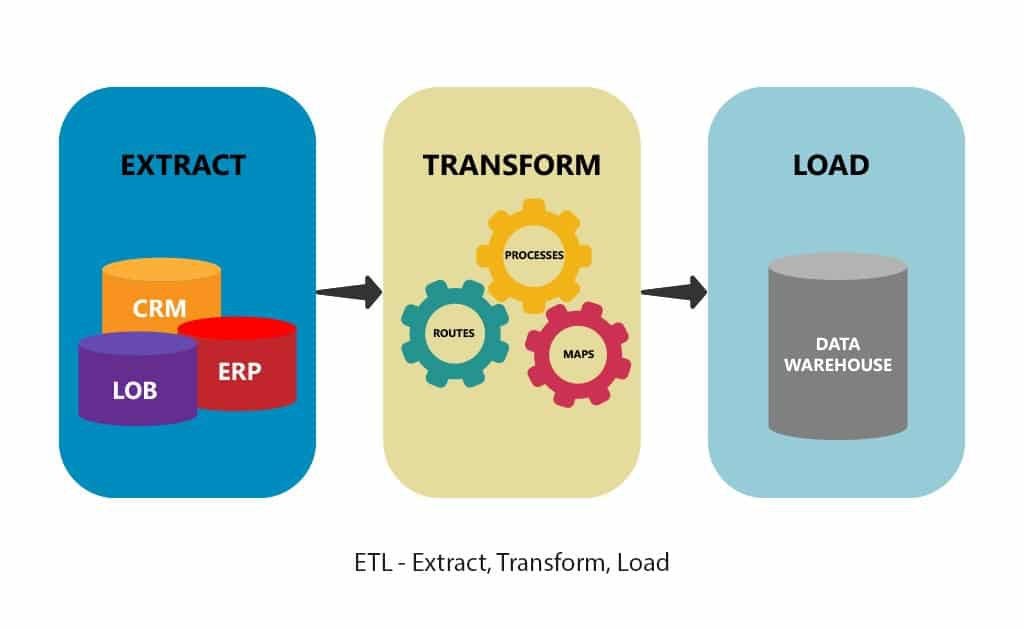
1. Extract – Menarik Data dari Sumber Beragam
Tahap pertama adalah pengambilan data dari berbagai sumber: database, API, file CSV, spreadsheet, bahkan sensor IoT. Tantangannya di sini adalah menangani format data yang berbeda-beda, termasuk data mentah yang tidak konsisten.
2. Transform – Membersihkan dan Menyesuaikan Data
Data yang diekstraksi jarang langsung bisa digunakan. Pada tahap transformasi, data dibersihkan, diformat ulang, dinormalisasi, dan disesuaikan dengan kebutuhan analisis. Proses ini juga bisa meliputi:
- Menghapus duplikat
- Mengisi nilai kosong
- Menggabungkan beberapa tabel
- Membuat fitur baru dari data lama
Jika Anda belum melakukan pembersihan awal, pelajari dulu proses data cleaning untuk mencegah error di tahap transformasi.
3. Load – Memasukkan Data ke Sistem Tujuan
Data yang sudah bersih dan siap pakai kemudian dimuat ke dalam data warehouse, database analitik, atau sistem pelaporan. Ini memungkinkan data dapat diakses oleh pengguna, analis, atau model machine learning.
ETL adalah Rantai Nyawa Infrastruktur Data
Tanpa ETL, proses analitik bisa berantakan. ETL menjamin bahwa:
- Data yang digunakan untuk analisis adalah terpercaya dan seragam
- Perubahan dari data mentah ke data siap pakai terdokumentasi
- Pengambilan keputusan berbasis data tidak mengandalkan asumsi
Dalam konteks perusahaan modern, ETL sering diotomatisasi menggunakan alat seperti Apache NiFi, Talend, Informatica, atau Airflow untuk efisiensi dan skalabilitas.
Contoh nyatanya: sebuah startup e-commerce menarik data transaksi dari aplikasi mobile (extract), membersihkan nama produk dan harga yang tidak konsisten (transform), lalu memuatnya ke dashboard BI untuk dipantau tim keuangan (load).
Tanpa pipeline ETL, insight semacam ini tidak akan mungkin didapatkan secara akurat dan real-time.
Bangun Proses Extract, Transform, Load yang Andal dari Sekarang
Jika Anda sedang mengelola data dalam skala besar atau mengembangkan sistem analitik, ETL bukan lagi opsi tambahan—tapi kebutuhan. Berikut langkah-langkah membangun proses ETL yang efektif:
- Identifikasi semua sumber data Anda
- Buat alur transformasi yang bersih dan terdokumentasi
- Automasi pipeline dengan tools seperti Apache Airflow atau Talend
- Monitoring hasil load secara rutin untuk deteksi error sejak dini
Kesimpulan
Extract, Transform, Load adalah fondasi sistem data modern. Tanpa proses ini, analitik akan terganggu, data menjadi bias, dan insight tidak dapat dipercaya. Proses ini memungkinkan organisasi mengintegrasikan data dari berbagai sumber, membersihkannya, menyelaraskannya dengan standar internal, dan menyediakannya secara konsisten untuk digunakan dalam pelaporan, prediksi, dan pengambilan keputusan strategis.
Di era data-driven decision making, siapa pun yang serius dalam bidang data perlu memahami dan menguasai ETL.
Baca juga : Apa Itu Data Mentah dan Cara Efektif Mengelolanya
![What is Exploratory Data Analysis? [Steps & Examples]](https://cdn-blog.scalablepath.com/uploads/2021/06/exploratory-data-analysis-900x615-1.png)






